

1. Stable Core Platform
You must have a solid core product to act as your central monitoring & observability platform.
What do I mean by this?
It must do the job you require it to do – not what the vendor says it can do and “sells” you as the benefits of buying their products.
It should be flexible enough to allow all the current and future integrations your business requires from an enterprise-class monitoring and/or observability solution.
If it doesn’t integrate with the things you need it to integrate with, don’t buy it.
The platform should be fully supported by the vendor through paid support options, 24×7 cover (if required), and ideally have a mature online platform and community where you can raise issues, support queries, initiate discussions, provide product feedback and more.
The cost should be fully understood, both initial and on-going. A discount to take up a product is always welcome (and should be pushed for), but not if the ongoing maintenance costs are astronomical. You don’t want any surprises.
The platform should be recognised in the industry. You don’t want to be an early adopter of a new platform that has just come onto the market, or has a small or immature customer base.
It should have a good, established client base, ideally with similar clients in your business niche, or at least with clients that are known to you and are of similar stature in terms of size, users, monitoring footprint etc.
The more recognised the platform is the more likely you will be able to find good people to implement and manage it, it in terms of future employees and contractors to help you get the most from the tools purchased.
If the vendor can’t provide and share case studies with you that should trigger warning bells.

2. Use Best of Breed Tools
Don’t expect or try and do everything in one tool, it might not be possible, despite what the product vendor might have told you!
Don’t be afraid to keep existing best of breed tools that your teams are currently happy with and simply consider how to integrate them into the core platform.
Similarly, if the core platform doesn’t have the monitoring capability for the technical domain you are trying to monitor effectively, then why not utilise the best of breed, industry-standard monitoring solutions for that technology stack, and integrate them into the enterprise monitoring framework you are creating?
- Maybe SCOM is better for monitoring windows than the core product offering you have?
- Maybe SolarWinds or NNMi are the better product for monitoring your network?
- Maybe your databases are configured using OEM but you need enhanced, centralised database monitoring such as that provided by Microfocus Operations Bridge Manager?
- Maybe you need specific scheduling software like Control-M or Autosys?
Many of the core platforms may include solutions to monitor these components, but are they the best solution?
If not then consider using a tool that does a better job, especially it it fits into your overall monitoring strategy and integrates seamlessly with your core platform.

3. Integration of Silo Tools
Teams that operate within their own silos (or tech-specific domains) often will have historically installed and deployed their own tools to manage their own estates.
But this can cause major issues with any centralised Enterprise Monitoring & Observability Solution.
I have seen teams “do their own monitoring” many times, often relying on emails and in-house poorly managed scripts to maintain their environment.
This can cause a multitude of problems…
- What if the emails aren’t received?
- Who monitors the emails out of hours?
- What if a server is patched or rebuilt and the monitoring scripts are deleted or simply stop working?
Such “team-specific” monitoring should be integrated (or migrated) into the overall monitoring strategy and core monitoring platform, so they are visible, controlled, managed and maintained effectively.
Teams should not simply be allowed to “do their own thing”, that’s a recipe for disaster.
If monitoring and alerts are critical to the successful running of a specific tech domain or team, then other tech teams (and possibly the rest of the business) must be notified accordingly where appropriate.
And of course, if these tools can’t be integrated with the core monitoring framework, or are not up to the job required by the business, then other monitoring solutions should be investigated immediately.
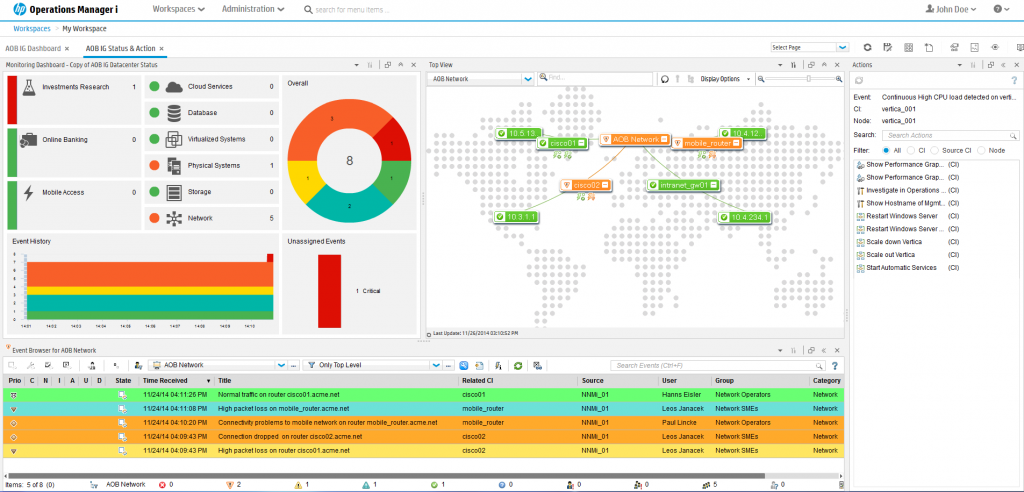
4. Effective Incident Management
For monitoring and alerting to work effectively, people need to know about it.
Whilst individuals and teams might get alerted to individual incidents, there must be escalation, correlation, and enrichment of data within the organisation so that all affected teams or users (actual and potential) have visibility of the issue.
A complete, mature and robust CMDB (Configuration Management Database) is essential.
All devices, servers, databases, networks and applications should have related CI’s (Configuration Items) defined and relationships between CI’s fully understood and mapped within the CMDB. The same for services – what CI’s make up a service? Has a service decomposition task been done?
Only in this way can the true impact of any one incident be understood in its entirety, managed effectively, and resolved successfully with minimal disruption to the business.
Incidents should be logged, notified, escalated, investigated, resolved and closed, with complete transparency to all interested parties.
Tools such as Remedy or ServiceNow are good examples of systems to manage this effectively.
Repeating incidents should trigger problem conditions automatically, so that recurring issues are spotted, tracked, managed and resolved so they don’t cause further damage or waste valuable resources.
An example of this could be a server with a spiking CPU utilisation at 3am, that appears to resolve itself within minutes. Left in isolation this could be ignored (assuming it has alerted correctly of course), thinking the problem has “gone away”. But what if this CPU spike caused an application on the server to have issues, which resulted in it not functioning properly at the start of the following business day?
That could cost the business heavily, especially in the financial markets.
What if a backup was failing each week, an incident was duly created, and every week the same support guy logs into the server and fixes the issue. Yes the incident has been solved, but the underlying problem has not been addressed as to why it keeps failing every week, and valuable (and often expensive) resources have been wasted unnecessarily.
I have been in organisations where this was commonplace – staff abusing the system purely for financial gain, and nobody did anything about it. Madness.
Similarly, major incidents should be throughly investigated via post-mortem activities whereby teams all come together to discuss the incident, the wider impact and then together the group can formulate a solution to ensure this never happens ever again, whether by fixing the underlying cause for good or by creating new monitoring to get better advanced warning of this potential outage.

5. Effective Notifications
There’s little point in monitoring anything if you don’t alert the right people in a timely manner to investigate.
Alerts sent via email may not get read…
Are the mailboxes monitored 24×7 for example?
Various notification tools exist such as PagerDuty, xMatters, SIGNL4 etc. (there are many on the market).
And some of these have other use cases too – for example call-tree / general notification for the business, so they can serve not just the monitoring tools but also BCP (business continuity planning), and major incident notifications such as bomb threats or terrorist activity etc.
Whatever alerting system you have, it should be centralised, controlled and monitored effectively – you can’t have 3 different systems all doing similar functions within the same organisation, that’s setting yourself up for failure.

6. Effective Reporting
There’s no point in reporting on anything if nobody will ever read such reports.
Many monitoring and observability tools will have some form of reporting built-in, but it’s not just about reports on CPU usage or uptime businesses care about (although infrastructure reporting can be useful for capacity planning).
Maybe you want to report on SEV1 and SEV2 tickets created over time (per team perhaps), or service availability.
Decide on what information is important to the business and the core teams within it, and ensure effective reporting is in place to provide adequate visibility to all interested parties.

7. Effective Performance & Capacity Management
This is not the same as monitoring!
How do you know when systems are running out of resources?
Capacity Management will give you an idea of current capacity levels and allow you to plan accordingly for future sizing and expansion where needed.
Performance Management tools are useful for performance testing of systems before go-live, application server sizing or stress testing / smoke testing to ensure your systems will be able to handle the data and workloads you expect of them.
Combining this with some of the AIOps tools and functionality that some monitoring and observability platforms provides will also allow you to predict failures, capacity and performance issues before they happen, keeping you one step ahead of potential resourcing disasters.

8. Observability Solutions
Observability solutions build on the traditional monitoring tools by providing a more complete picture of what is happening in an environment, across multiple data sources.
Whilst monitoring might look at metrics and logs for “error” conditions, it doesn’t give the end to end visibility of why something happened or the impact to other areas, or the core business.
Traditional monitoring doesn’t alway provide the holistic big picture view of the impact of an alert, and often doesn’t allow you to drill-down to see exactly what was happening in multiple areas at the time of a problem.
By combining monitoring with data from logs and traces and other sources you can better understand the overall impact of an alert, and are able to pinpoint how other data sources have been impacted and utilise big data to see a more complete picture of what happened and why.
Observability solutions will often allow you to map the overall health of essential services within the business, showing key metrics, customer journeys and detailed application level monitoring, all displayed in meaningful customisable dashboards that can serve many persona use cases, for example engineers, service owners, and business leaders.
The crucial thing here is not to purely focus on observability – monitoring and alerting need to be addressed in parallel, else all you’re doing is showing dashboards of noise to everyone, and no AIOps solution can clarify that for you, despite what the product (or sales) hyperbole says.